Explainer
What Is Voxtral TTS?
Voxtral TTS is an open-source text-to-speech model developed by Mistral AI, released in March 2026 with 4 billion parameters. It converts text into natural, expressive speech across 9 languages and supports zero-shot voice cloning from as little as ~3 seconds of reference audio.
Voxtral TTS at a glance
- Release
- March 2026
- Model size
- 4B parameters
- Latency
- ~70ms (typical)
- Languages
- 9
- License
- CC BY NC 4.0
- Voice cloning
- Zero-shot (≈3s reference)
How Does Voxtral TTS Work?
Voxtral treats voice as an instruction. Instead of extracting a static “voice fingerprint” in a separate step, it processes the reference audio and the target text together—so timing, tone, and emotional cues emerge naturally without prosody tags or fine-tuning.
The model is also designed for real-time pipelines, reaching roughly 70ms latency for typical inputs—one reason it’s a strong fit for voice agents and interactive experiences.
Workflow preview

1) Input Text
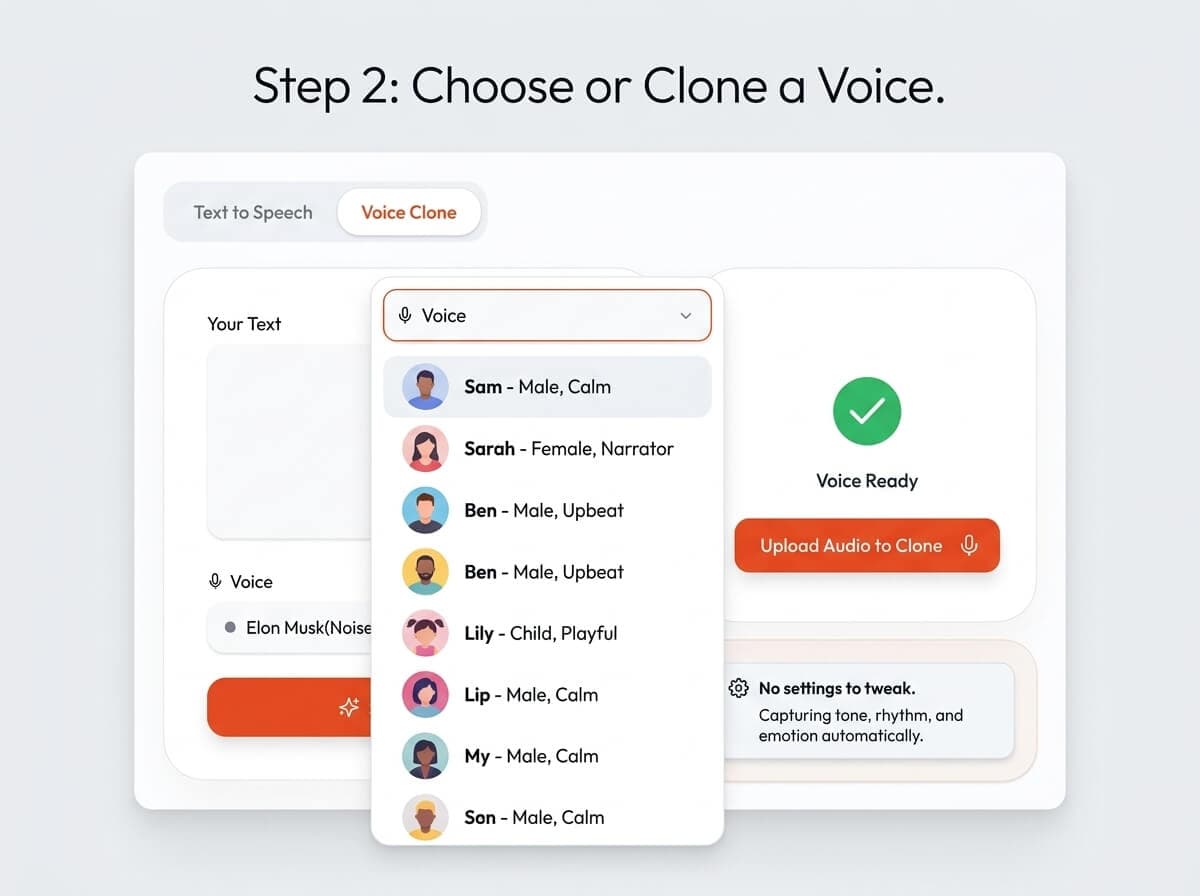
2) Add Voice Prompt
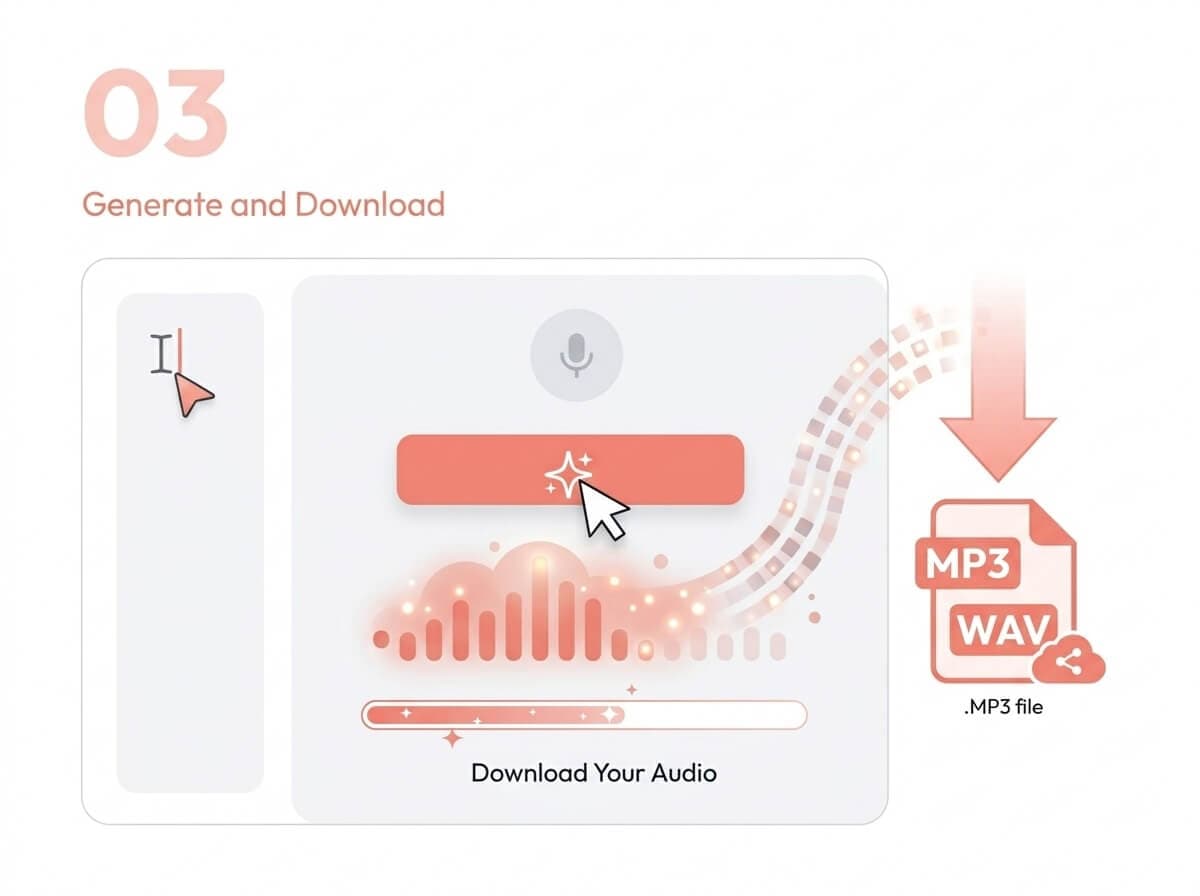
3) Generate Speech
Key Features of Voxtral TTS
Zero-shot voice cloning
Clone a voice from short reference audio—no training pipeline required.
See cloning deep dive →Ultra-low latency
Designed for interactive use cases like agents, IVR, and streaming.
Compare latency vs OpenAI →9-language native support
One model covers 9 languages, suitable for multilingual products.
See usage guide →Self-hosting option
Open weights enable private deployment and predictable costs at scale.
See pricing options →Voxtral TTS vs Other TTS Models
Voxtral TTS sits at the intersection of quality, real-time performance, and open infrastructure. Compared with proprietary APIs, it’s notable for enabling self-hosting and for its low-latency profile.
What Can You Use Voxtral TTS For?
Podcasts & content
Generate consistent narration at scale without recording every iteration—useful for intros, explainers, and localization.
Customer support & IVR
Low latency helps reduce “AI silence” in interactive flows, improving perceived responsiveness.
Games & NPC dialogue
Generate dynamic speech on-demand and personalize character voices with short reference prompts.
Enterprise deployment
Open weights support private GPU deployments when data sovereignty is a requirement.
How to Get Started with Voxtral TTS
- 1) Paste your text (script, prompt, article, etc.).
- 2) Choose a voice or upload a short reference clip for cloning.
- 3) Generate and download audio as MP3/WAV.
Frequently Asked Questions About Voxtral TTS
What is Voxtral TTS?
Voxtral TTS is Mistral AI's open-source text-to-speech model, released in March 2026 with 4 billion parameters. It turns written text into natural speech across 9 languages and supports zero-shot voice cloning from ~3 seconds of reference audio.
Who made Voxtral TTS?
Voxtral TTS was developed by Mistral AI. The model weights are published on Hugging Face and the hosted inference is available via Mistral's API.
Is Voxtral TTS free?
The model weights are open and free to download. Licensing is CC BY NC 4.0 (non‑commercial). For commercial usage, teams typically use Mistral's API terms or a commercial arrangement depending on their deployment.
What languages does Voxtral TTS support?
Voxtral TTS supports 9 languages: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
Can Voxtral TTS clone any voice?
Voxtral TTS supports zero-shot voice cloning from short reference audio. Clean recordings work best; longer clips (5–10 seconds) typically improve fidelity, but ~3 seconds is enough to start.
Is Voxtral TTS open source?
Yes. Voxtral TTS is released under CC BY NC 4.0 with weights available publicly, which also enables self-hosting for teams that want infrastructure control.
How does Voxtral TTS compare to ElevenLabs?
Voxtral emphasizes open weights, self-hosting, and low latency. ElevenLabs typically offers broader language coverage. For a detailed breakdown, see our comparison page. Voxtral TTS vs ElevenLabs.
Can I self-host Voxtral TTS?
Yes. Because the model weights are available, Voxtral TTS can be deployed on your own GPU infrastructure for privacy, control, and cost predictability at scale.